R中的概率分布函数
rnorm: 根据给定的平均值和标准偏差生成随机正态变量dnorm: 计算一个点或点向量的正态概率密度(根据给定的平均值/ 标准偏差)pnorm: 生成正态累积分布函数rpois: 根据给定的比率生成随机泊松分布随机数
每种概率分布函数通常有四种前缀
d密度r生成随机数p累积分布q分位数函数
生成正态分布可以使用以下四个函数
dnorm(x, mean = 0, sd = 1, log = FALSE)
pnorm(q, mean = 0, sd = 1, lower.tail = TRUE, log.p = FALSE)
qnorm(p, mean = 0, sd = 1, lower.tail = TRUE, log.p = FALSE)
rnorm(n, mean = 0, sd = 1)
如果 $\Phi$ 是标准正态累积分布i, 那么pnorm(q) = $\Phi(q)$ , qnorm(p) = $Φ^{−1}(p)$。
> x <- rnorm(10)
> x
[1] 0.3357161 -0.4786192 0.3952794 -1.5230122 -0.6496318 -1.2714863 0.6367861
[8] -0.8809022 -0.4377379 -0.3063769
> x <- rnorm(10, 20, 2)
> x
[1] 16.15086 15.89892 23.22139 20.60856 25.15596 18.85948 19.50671 20.81849
[9] 17.82214 18.43590
> summary(x)
Min. 1st Qu. Median Mean 3rd Qu. Max.
15.90 17.98 19.18 19.65 20.77 25.16
使用 set.seed 函数设定随机数种子以保证结果的可重复性
> set.seed(1)
> rnorm(5)
[1] -0.6264538 0.1836433 -0.8356286 1.5952808 0.3295078
> rnorm(5)
[1] -0.8204684 0.4874291 0.7383247 0.5757814 -0.3053884
> set.seed(1)
> rnorm(5)
[1] -0.6264538 0.1836433 -0.8356286 1.5952808 0.3295078
在进行模拟时最好设置随机数种子
生成泊松分布数据
> rpois(10, 1)
[1] 0 0 1 1 2 1 1 4 1 2
> rpois(10, 2)
[1] 4 1 2 0 1 1 0 1 4 1
> rpois(10, 20)
[1] 19 19 24 23 22 24 23 20 11 22
## 累积分布‘
## x <= 2的概率分布
> ppois(2, 2)
[1] 0.6766764
## x <= 4的概率分布
> ppois(4, 2)
[1] 0.947347
## x <= 6的概率分布
> ppois(6, 2)
[1] 0.9954662
通过线性模型生成随机数
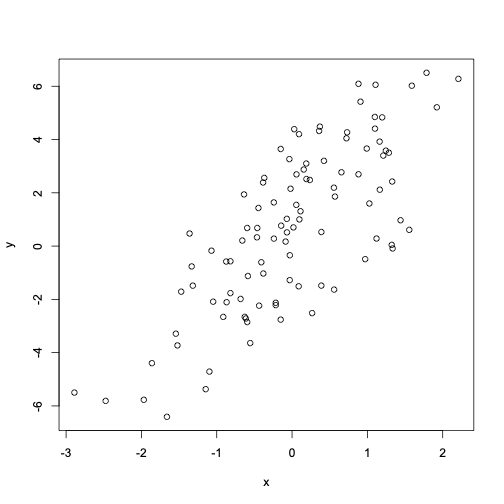
通过 $y = \beta_0 + \beta_1 x + \varepsilon $ 模型生成随机数。 已知$\varepsilon\sim\mathcal{N}(0, 2^2)$. Assume $x\sim\mathcal{N}(0,1^2)$, $\beta_0 = 0.5$ , $\beta_1 = 2$。
> set.seed(20)
> x <- rnorm(100)
> e <- rnorm(100, 0, 2)
> y <- 0.5 + 2 * x + e
> summary(y)
Min. 1st Qu. Median Mean 3rd Qu. Max.
-6.4084 -1.5402 0.6789 0.6893 2.9303 6.5052
> plot(x, y)
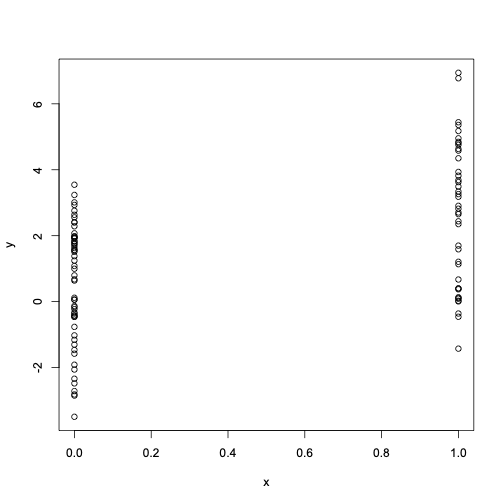
当 x 为0或1时
set.seed(10)
x <- rbinom(100, 1, 0.5)
e <- rnorm(100, 0, 2)
y <- 0.5 + 2 * x + e
plot(x, y)
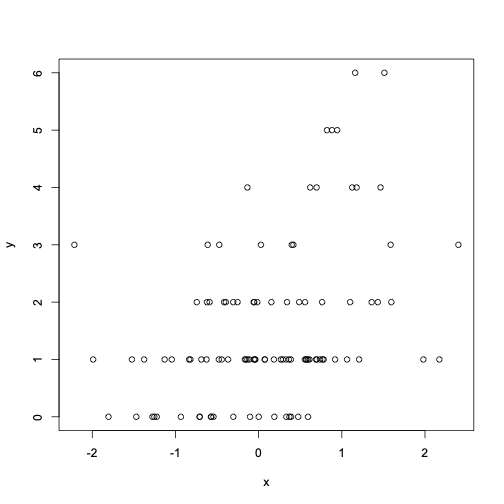
通过广义线性模型生成随机数
模拟泊松模型:Y ~ Poisson(μ)
log μ = $\beta_0 + \beta_1x$
已知 $\beta_0 = 0.5$ 和 $\beta_1 = 0.3$。
使用 rpois 函数生成随机数
set.seed(1)
x <- rnorm(100)
log.mu <- 0.5 + 0.3 * x
y <- rpois(100, exp(log.mu))
summary(y)
plot(x, y)
生成随机样本
sample 函数可以从一个指定的组合中生成随机样本。
> set.seed(1)
> sample(1:10, 4)
[1] 3 4 5 7
> sample(1:10, 4)
[1] 3 9 8 5
> sample(letters, 5)
[1] "q" "b" "e" "x" "p"
## 随机排列组合
> sample(1:10)
[1] 4 7 10 6 9 2 8 3 1 5
> sample(1:10)
[1] 2 3 4 1 9 5 10 8 6 7
## 随机替换,生成可重复的样本
> sample(1:10, replace = TRUE) ## Sample w/replacement
[1] 2 9 7 8 2 8 5 9 7 8
小结
r*系列函数根据特殊的概率分布生成随机数- 内置的正态分布:标准,泊松,二项式,指数, 伽马等
sample函数提取随机样本- 通过set.seed函数生成随机数生成种子,保证结果的可重复性